Adaptive Grey-Box Fuzz-Testing with Thompson Sampling
Abstract
模糊测试或“fuzzing”是指广泛部署的一类技术,用于通过生成一组输入来测试程序,以明确查找错误和识别安全漏洞。灰盒模糊测试是最流行的模糊测试策略,它将轻型程序设备与数据驱动过程相结合,以生成新的程序输入。在这项工作中,我们提出了一种机器学习方法,它建立在AFL(一种卓越的灰盒模糊器)之上,通过在特定程序的基础上自适应地学习其变异算子的概率分布。这些算子在AFL和突变模糊器中随机均匀选择,决定了新输入是如何产生的,这是模糊器功效的核心部分。我们的主要贡献是双重的:首先,我们表明,根据训练计划估计的变异算子的采样分布可以显着提高AFL的性能。其次,我们介绍了一种基于强盗的Thompson Sampling优化方法,该方法可以在模糊单个程序的过程中自适应地调整mutator分布。跨越复杂程序的一组实验表明,调整突变运算符分布会产生一组输入,这些输入产生的代码覆盖率显着提高,并且比基线版本的AFL以及其他基于AFL的学习方法更快,更可靠地发现崩溃。
KEYWORDS:binary fuzzing; coverage-based fuzzing; thompson sampling
| relevant information | |
|---|---|
| 作者 | Siddharth Karamcheti;Gideon Mann;David Rosenberg |
| 单位 | Bloomberg CTO Data Science New York, NY, USA |
| 出处 | AISec’18 |
| 原文地址 | https://arxiv.org/pdf/1808.08256.pdf |
| 源码地址 | |
| 发表时间 | 2018年 |
1. 简介
程序模糊测试,或模糊测试[8,11,13,14,22,26]是一组技术,可为程序生成各种意外和不同的输入,执行和记录它们覆盖的尚未测试的程序部分,导致崩溃或挂起,或识别任何意外行为。最有前途的基于反馈的模糊器是Gray-Box Mutational Fuzzers,例如AFL(“American Fuzzy Lop”)[32],它依靠轻量级二进制插桩和遗传算法迭代地改变输入以增加代码覆盖率。 AFL已经广泛部署,消除了几个流行的软件应用程序中的漏洞,包括Mozilla Firefox,Adobe Flash和OpenSSL [33]。 AFL选择先前的父种子进行采样,对其应用一组变异函数(数量和类型),并使用新的子种子执行程序,如果发现新的代码路径,则将子项添加到队列中。
虽然有大量的工作正在研究使用数据驱动技术改进greybox模糊测试(以及特定的AFL),但工作主要集中在选择最有希望的父输入(或输入子序列)进行变异。例如,Lemieux和Sen [18]提出了一种名为FairFuzz的AFL新变种,它专注于在程序控制流图中对突变分支进行突变的种子变异。另外,Rajpal等人 [24]使用深度神经网络来了解输入的哪些部分对应于不应模糊的魔术字节或边界(例如PDF标题),在较少受约束的字节位置上聚焦模糊效应。一个相对较少探索的领域是调整突变过程本身的改进。例如,考虑一个执行两个命令行输入的进位加法的简单程序;在这种情况下,任何插入字符串或非数字类型的变异操作符都将导致触发顶级错误处理代码的输入。相反,我们希望优先考虑导致有趣数值的mutator,以创建深入到程序中的输入。
在这项工作中,我们展示了如何学习变异算子分布以生成显着改进AFL的新孩子 - 这个简单的过程比父母选择技术提供更大的收益。我们重新设计AFL的模糊环路作为一个多臂强盗问题,其中每个臂对应一个不同的变异算子,并表明通过使用Thompson采样[1],我们可以在模糊过程中自适应地学习更好的运算符分布,在模糊单个程序中,获得了更好的结果。我们在DARPA网络大挑战二进制文件[7]上的结果,这是一套由人类开发并充满天然错误的程序,这表明我们的Thompson采样方法导致代码覆盖率显着增加,并且发现的崩溃数量超过其他状态。现代模糊器,包括AFL版本2.52b和FairFuzz [18]。为了完整起见,我们还评估了LAVA-M合成缺陷数据集[10],其中我们显示的结论较少,可能是由于样本量较小(该集合仅包含4个程序),以及缺陷的合成性质。总而言之,我们对超过75种独特二进制文件的实验表明,自适应地调整mutator分布比现有的模糊器如AFL和FairFuzz产生了显着的好处。
2.模糊概述
模糊器按其所需的测试程序的透明度进行分类。黑盒模糊器[12,15,17,30]通过非常快速地生成大量随机输入来操作,而没有关于被测试代码的任何信息。最简单的黑盒模糊器是随机模糊器,如Radamsa [15]和ZZUF [17]。这些工作通过采样字符串长度,然后采样字符或位来随机均匀生成。这些类型的模糊器运行得非常快,并且通常用于模糊工具以检查用户提供的字符串是否满足特定要求(例如密码检查器)。虽然他们可以快速找到被测程序顶层的浅层错误,但它们需要花费很长时间才能发现嵌套错误。
在程序透明度的另一个极端,White-Box模糊器[11]和符号执行工具[2,9,20,21,23,28]如KLEE [6]和SAGE [14]象征性地操纵源代码以确定性地发现探索每个代码路径的输入序列。由于他们能够遍历整个源代码树,因此他们可以发现嵌套代码中的错误。这些工具在LLVM IR之类的代码的中间表示上运行,或者假设高级源代码信息。这些工具使用约束求解器来明确求解到达代码中某些分支点的输入,结果随着程序变大而降低[2,16]。
灰盒模糊
在这两个极端之间是Gray-Box模糊器[4,18,19,25,27,32]。这些模糊器假设可以将轻量级插桩注入程序或二进制文件以确定覆盖范围。这允许模糊器识别何时找到执行新代码路径的输入。虽然有不同类型的灰盒模糊器,但到目前为止最有效的是突变模糊器,它使用遗传算法将父输入“变异”为新的子输入,允许人们推断出类似的输入如何影响程序的执行。

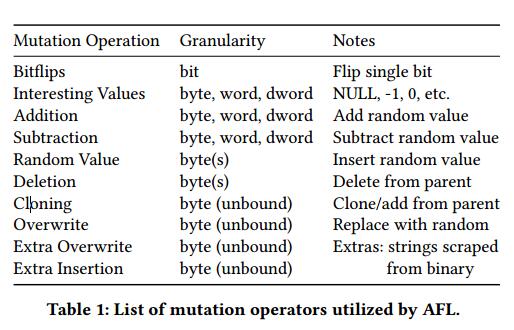
突变灰盒模糊的一般草图可以在算法1中找到。虽然图中描述的算法是AFL特有的,突出的突变灰盒模糊器,一般算法在所有突变模糊器中采用相同的形式,具有不同的特性在启发关键功能的启发式算法(pick_input,sample_mutation等)。作一个简短的总结,这些模糊器通过维护一个输入队列来运行不同的代码路径。然后将模糊测试过程简化为算法1的第6和第8行上的两个循环,外循环(第6行)负责从该队列中拾取输入和相应的能量值(pick_input)。可以将能量看作花费给定父输入的时间量(从算法1运行内循环的迭代次数)。然后,内循环(第8行)负责通过应用特定变异函数(sample_mutation)的随机数(sample_num_mutations)从父进程创建新的子输入。这些变异函数包括随机位移,随机字节,添加“魔术”字节,位级算术运算等,并应用于特定字节集(sample_mutation_site)的所选输入以创建新子节点候选人。 AFL使用的变异运算符的综合表可以在表1中找到。然后执行该子候选项,并且如果它执行的代码路径与已经记录的输入所执行的代码路径不同,则将其添加到队列中。
2.1 AFL
最受欢迎和广泛采用的灰盒子模糊器之一是“American Fuzzy Lop”[32]或AFL。由于我们在AFL之上构建我们的方法,因此理解其优势及其局限性是值得的。算法1详细介绍了AFL算法的核心;然而,虽然这突出了AFL背后的主要循环,但它没有强调一些关键细节。
第一个是AFL的反馈驱动覆盖机制。 AFL既有效又聪明;在模糊测试期间,它可以每秒执行数百个输入,遍历大量的程序输入空间,同时优化代码覆盖。它通过将轻量级插桩注入到测试程序中来实现此目的,以跟踪输入通过程序的路径。它的工作原理如下:AFL首先为程序中的每个基本块分配一个随机ID。然后,这些块ID计算边缘ID(识别从一个基本块到另一个基本块的转换,或程序控制流图中的边缘),允许AFL跟踪路径。具体而言,AFL存储一个位图,该位图将转换映射到粗略的“命中计数”(单个输入观察到给定转换的次数)。任何观察到尚未看到的转换的输入都被认为是“有趣的”,并被添加到队列中(算法1的第14行)。这种跟踪工具既可以在编译时注入(通过使用文件编译程序或使用AFL附带的fl-编译器编译),也可以在运行时通QEMU仿真器注入,从而允许AFL模糊闭源二进制文件。在我们的实验中,我们专门研究二进制文件,利用这种QEMU模式。
第二个细节涉及AFL的pick_input实现,或者如何选择下一个模糊的队列条目。请注意,在算法1的第5行,pick_input函数将队列作为参数使用,并返回两个输出,“父”或实际队列条目以变异为新子项,以及“能量”值,对应花费多少时间(在第6行开始的内部循环的迭代)给定的父级。 AFL仅基于启发式实现此功能:即,AFL根据以下因素确定为每个队列条目分配能量的calculate_score函数:覆盖范围(优先考虑覆盖更多程序的输入),执行时间(优先执行更快执行的输入) )和发现时间(优先考虑后来发现的输入)。
最终细节与AFL的操作模式有关。该模糊器目前有两种不同的模式,AFL和FidgetyAFL,正如AFL的开发人员以及之前的工作[18,31]所述。虽然两个版本的AFL的核心是算法1中描述的循环,但关键的不同之处在于标准AFL在启动主模糊环之前在每个父输入上运行一系列受控的确定性突变。这些确定性突变按顺序在队列中每个输入的每个位/字节处运行,并包括以下操作[34]:
- bit flips,具有不同的长度和偏移。
- 算术运算(加/减小整数)。
- 插入“有趣”整数(来自包括0,1,MAX / MIN_INT等的有限集合)。
这些确定性突变的目标是创建捕获输入空间中固定边界的测试用例。然而,之前的工作[3,4],以及主要的AFL开发人员[31]注意到,在许多程序中,人们可以通过省略这个确定性阶段来获得更多的覆盖范围并发现更多的崩溃。实际上,没有这个确定性阶段的AFL恰好是FidgetyAFL,或算法1中描述的循环(AFL以“-d”参数运行)。在我们的实验中,我们利用AFL和FidgetyAFL作为基线(FidgetyAFL几乎总是两者中更强大的模糊)。两种版本的AFL最终都进入算法1的循环。AFL从21到27之间的2的幂集合中随机均匀地选择应用许多突变(sample_mutations()在算法1的第8行)。算法1的第9行上的变异算子(sample_mutation())也是从表1中的16个运算符的集合中随机选取。应用给定变异的站点(算法1的第10行上的sample_mutation_site())也在父对象的字节上随机均匀选择。
3.相关工作
有大量工作专注于学习更好的启发式方法来选择模糊输入(算法1第5行的pick_input)。Böhme等人 [3]和Rawat等人 [25]学会在能量值之外选择队列中的输入,以最大化击中程序的所需部分的概率,或者练习所需的代码路径(如果想要在程序中模糊某个功能,他们应该优先考虑队列中的输入,这些输入使用给定函数来执行代码路径。这两种方法都使用轻量学习(在Böhme等人的案例中[3],一个学习的能量调度)建立在AFL之上,并显示出强有力的结果。此外,Böhme等人[4]基于覆盖的概率模型,引入了一组用于优化模糊测试的算法。他们介绍了AFLFast,这是一种AFLvariant,它引入了新的搜索策略和功率调度,以最大限度地提高代码覆盖率。具体来说,作者能够证明他们的方法在GNU binutils(一组标准的Linux程序)上胜过AFL和FidgetyAFL [31]。
最近,Lemieux和Sen [18]介绍了FairFuzz,这是另一种优化pick_input的技术。具体来说,作者的假设是,在程序中崩溃并改善代码覆盖率的最佳方法是优先考虑执行稀有分支的输入。通过专注于对这些输入进行模糊测试,FairFuzz可以生成许多新的输入,这些输入可以达到程序的极限,从而消除了大量的错误。 FairFuzz还通过跟踪输入中的哪些字节导致控制流的变化来优化突变位点(pick_mutation_site)的选择。他们使用它来防止触发器接触输入缓冲器的易失区域。 [18]中的结果表明,FairFuzz比当前版本的AFL,FidgetyAFL和AFLFast更有效 - 使其成为这项工作时发布的最有效的灰盒模糊器。相关的,Rajpal等[24]使用深度神经网络来选择变异位点(pick_mutation_site),以防止模糊器创建无法通过错误处理代码或语法检查的简单输入。具体来说,作者表明他们可以有效地模糊PDF解析器,并生成非平凡的PDF。
所有上述模糊器都会使突变操作符的分布不受影响,默认为AFL附带的均匀分布。研究突变分布的少数工作之一Böttinger等人的研究 [5]将灰盒模糊作为强化学习问题,并使用Q-Learning [29]来学习选择变异算子的策略。虽然这种方法非常有趣,但它们只评估单个程序(PDF解析器),单个队列条目保持固定,而不是在模糊测试期间调整队列。而且,他们的基线是随机模糊器而不是AFL。在这里,我们与一组标准程序上的最先进的模糊器进行比较。
4.方法
在本节中,我们将介绍估算灰盒模糊变换器分布的方法的详细信息。第4.1节给出了一些motivating的例子,第4.2节规定了一种学习更好的静态分布的方法(用于验证确实存在比AFL使用的均匀分布更好的变异分布),第4.3节介绍了我们的自适应汤普森抽样方法。
4.1motivating示例
为了理解变异器分布对模糊效率的影响,我们提出了两个motivating的例子。我们走过的两个例子都是DARPA网络大挑战(CGC)数据集[7]的一部分。它们具有不同的功能和不同的复杂程度,正如现实世界的人类写的代码一样。
4.1.1 ASCII内容服务器
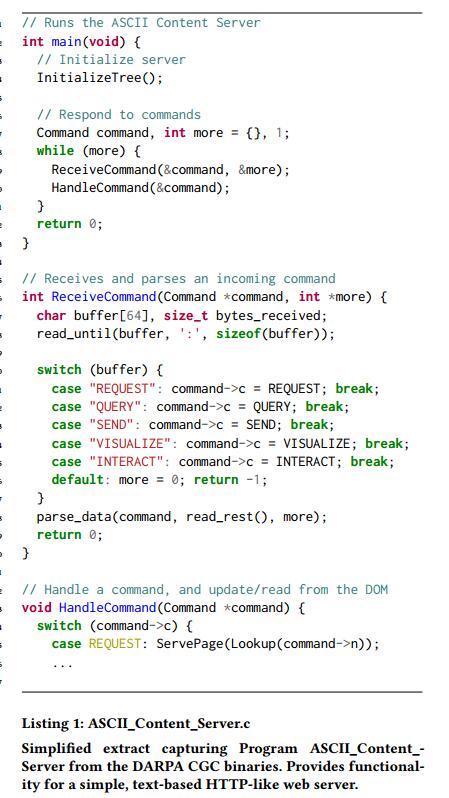
第一个示例可以在清单1中找到,它是C程序ASCII_Content_Server的简化摘录,它演示了基于文本的简单HTTP Web服务器的顶级功能。该程序支持启动Web会话的功能,其中用户(通过STDIN)可以发出一系列命令来创建网页(“SEND”),查找,交互和可视化页面(“QUERY”,“INTERACT” “,”VISUALIZE“),并发出API调用(”REQUEST“)。会话可以由任意多个命令组成,因为它们都是通过STDIN指定的。但请注意,每个命令都以给定类型的关键字(作为字符串)开头,后跟给定命令的数据(例如“REQUEST < DATA >”)。
在本程序的上下文中考虑表1中列出的变异运算符。许多这些增变器在比特级别(例如,比特流量,加法/减法)随机地操作。特别是因为这些变异算子的位置也是均匀分布的,这些位级运算符在为程序产生良好输入方面证明效率较低,因为它们很有可能与表示命令的关键字字符串(例如“REQUEST”)发生冲突。因此,相应的子输入将很可能最终导致格式错误,触发第26行的默认错误处理代码。这可以防止模糊测试者深入探索程序,就像在mutator上均匀分布一样,有趣的输入只会很小的概率被产生。
相反,为了增加产生有趣输入的可能性,重新考虑表1中的变换器。即,考虑插入/覆盖“额外”的变换器(在这种情况下,关键字字符串“REQUEST”,“QUERY”等),以及从父种子克隆字节。这两个mutator都更有可能产生有趣的输入,因为它们更有可能导致输入良好的输入以通过ReceiveCommand函数中的语法检查。实际上,尤其是在模糊测试过程的后期,人们可能会期望克隆变异器更加有效,因为它会将更长和更长的命令会话复制到子输入中,从而允许更复杂的会话可能触发非平凡的错误。
4.1.2 ASL6解析器
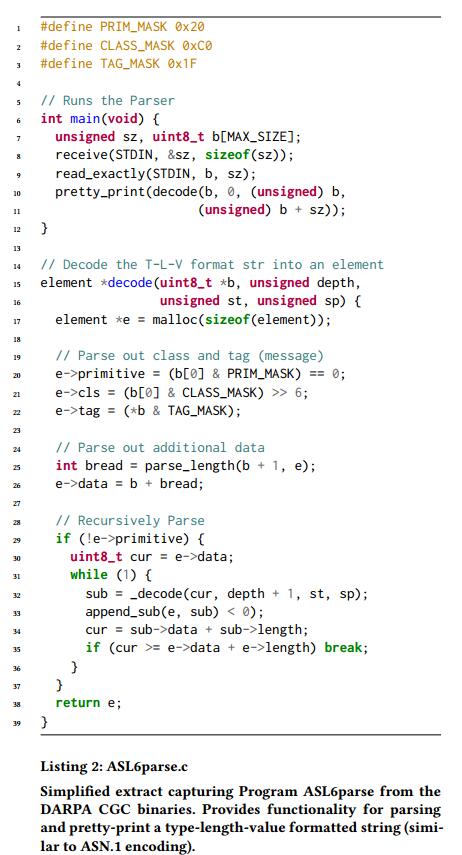
第二个例子可以在清单2中找到,这是C程序ASL6parse的简化摘录。 ASL6parse为ASL6格式化标准提供了递归解析功能,ASL6格式标准是一种类似于ASN.1编码的类型 - 长度 - 值格式。该程序提供的功能核心包括通过STDIN读取任意长ASL6编码的字符串,将其解码为更易于人类阅读的格式,然后将结果漂亮打印到屏幕上。每个ASL6字符串采用一系列消息的格式,其中每个消息由三个值组成:1)类型或类,2)长度值,指定给定值具有多少个字符(以便于阅读),以及3)字符串值,由基元或一个或多个嵌套消息组成。
与之前的程序不同,ASL6parse不依赖于任何关键字或特定字符串值;实际上,每个标记/类都是通过按位和初始位来找到的,并且使用常量“TAG_MASK”。因此,深入探索程序所需的一切就是生成更复杂的字符串,这些字符串松散地遵循放宽ASL6格式。如果我们考虑表1中的变换器,我们会看到那些优先考虑随机插入的算法,加上那些算术运算符(用于表示长度值)更有可能为程序产生有趣的输入,而不是那些覆盖/插入字符串值的输入 - 有效的分配将优先考虑前者,并对后者进行去优先排序。
值得注意的是,在两个不同的程序中,非常需要对mutator进行极大的不同分布(注意ASCII_Content_Server的最有效的mutator如何对ASL6parse影响最小)。很明显,学习非均匀分布的解决方案可以提高产生深入到程序中的输入的可能性。
此外,该解决方案需要具有适应性,能够在每个程序的基础上了解哪些运营商比其他运营商更有效。
4.2根据经验估计分布
我们的假设是优化模糊测试的最佳方法是自适应地学习变异分布。然而,有必要评估是否存在比AFL使用的均匀分布更好的fixed mutator分布,以了解AFL当前启发式的准确性。为此,我们概述了一种方法,通过分析和推断一组与我们测试的程序无关的一组完整的模糊测试运行来定义fixed发行版。直观地说,这里的目标是使用在不相关程序上收集的数据来学习一种新的mutator分布,它比开箱即用的AFL表现更好。虽然这种经验估计的静态分布对于单个程序来说并不是最佳的(因为它没有自适应调整),但我们学习它的方法有两个主要的好处:1)它让我们了解AFL当前的低效率,同时提供一个强大的点我们的自适应Thompson采样策略的比较,以及2)它允许我们提供关于如何使用数据来通知选择mutator分布的直觉,然后深入研究下一节(第4.3节)中详述的自适应Thompson采样方法。
我们用于估计mutator上更好的平稳分布的方法很简单。回想一下,与大多数模糊器一样,我们优化的度量标准是代码覆盖率 - 我们希望最大化我们发现的代码路径数量(同样,崩溃或挂起等其他指标过于稀疏和随机,无法用作有意义的成功信号)。我们的方法很简单:将来成功的变异算子的最佳指示是过去成功的变异算子。
请考虑以下内容:设c~k~对应于创建成功输入时使用变异运算符k的次数。一个成功的输入是一个探索新代码路径的子变种。我们可以通过向AFL添加一些轻量级代码来跟踪这个数量,以记录每个突变体的突变计数。有了这些总计数,我们可以估算一个新的分布如下:
$$
p_k =\frac {c_k}
{\sum_{K′=1}^K c_{k′}}
$$
其中p~k~是从K个可能的突变中选择变异算子k的概率。注意,这里分母的作用仅仅是为了确保概率p~k~总和为1。基于成功计数的概率参数的这种估计恰好是最大似然估计。捕获这种方法的效果的结果可以在6.2节中找到。
4.3汤普森抽样
在本节中,我们推导出自适应地学习变异算子分布的方法。这种方法的直觉类似于前一节的直觉;我们应该优先考虑过去成功的变异算子。然而,与之前不同的是,我们在大量程序的许多完整模糊运行结束时估计了我们的分布,这里我们没有相同数量的数据,也没有相同的统计度,因为我们正在研究单独的程序,我们在短时间的模糊测试后开始估算新的分布。相反,我们需要一种方法,允许我们考虑我们对估算的信任,从谨慎开始,然后在收集更多数据时变得更加确定。给我们这种行为的一种方法是Thompson Sampling [1]。
Thompson Sampling是经典的多武装强盗问题的一种方法。在多武装强盗中,设置如下:有K个老虎机(“强盗”),每个都有未知的报酬概率。问题在轮次中进行,并且在每一轮中,我们可以选择一个K强盗来玩。根据每个强盗使用的分布族,我们会看到一些奖励。例如,在伯努利强盗设置中,每个强盗的报酬是从伯努利分布中得出的,对于给定的强盗k,由θ~k~参数化 - 强盗k将以概率θ~k~报酬为1,概率1-θ~k~报酬为0。
直观地,每个θ~k~对应于玩给定强盗的成功概率。为了最大化奖励,最好以最高的成功概率发挥作用。换句话说,如果我们有完整的信息,并且知道每个强盗手臂的参数θ~1~,θ~2~,…. θ~K~,最佳策略是始终发挥k~best~ = arg max~k~θ~k~。但是,我们没有这方面的信息。因此,我们需要在尝试各种强盗之间进行交易以估计其报酬的概率,并提交目前为止看似最好的土匪。
我们设置了自适应估计变异器上的分布作为多武装强盗问题的问题,如下所示:让每个变异算子1,2…. K(表1中详述的16个操作员)是一个不同的强盗。对于每个变异算子,让θ~k~为相应运算符用于生成成功输入(增加代码覆盖率的输入)的可能性。最后,不要像在标准的多武装强盗部分中那样选择“最佳”武器,而是将变异操作符的分布设置为:
$$
p_k =\frac {θk}
{\sum{K′=1}^K θ_{k′}}
$$
其中p~k~是在模糊测试期间选择操作员k的概率。
有了这个,剩下的就是制定处理勘探开发贸易的细节,并最好地学习每个θ~k~。
4.3.1Exploration-Exploitation 。
Thompson Sampling将勘探开发贸易框架视为贝叶斯后验估计。回到传统的多武装强盗设置,我们从每个K强盗π(θ~1~),π(θ~2~),…π(θ~K~)的先验分布开始。这个先验首先被设置为反映每个强盗的参数如何设置的起始信念(在我们的例子中,我们的先验是AFL在运算符上的分布 - 即均匀分布)。然后,让D~t~成为我们在第一轮比赛中收集的数据,我们可以通过对(n~10~,n~11~),(n~20~,n~21~),… (n~K0~,n~K1~)表示,其中n~k1~是给定手臂导致报酬为1的次数,其中n~k0~是给定手臂导致报酬为0的次数。所以,如果我们看所有的我们通过循环 t 收集的数据,在所有臂上,我们看到
$$
\sum_{K= 1}^k(n_{k0} + n_{k1})= t
$$
假设我们刚刚完成了循环t,观察数据D~t~。我们希望将我们的数据D~t~与我们的先前知识相结合,并收集每个手臂的后验分布。这些后验分布π(θ~1~| D~t~),π(θ~2~| D~t~),… π(θ~K~| D~t~)代表我们对θ~1~,θ~2~,… θ~K~的值的合理更新信念。一旦我们得到这些后验分布,问题仍然存在:我们应该在第t + 1轮比赛中选用哪个强盗?一种贪婪的方法是选择最有可能成为最好的强盗(具有最高θ~k~的强盗k) - 但这是所有的剥削,而不是探索。 Thompson Sampling方法以一种有趣的方式妥协:对于每个强盗k,样本θk ~ π(θ~k~| D~t~)。然后,玩强盗k’= arg max~k~θ~k~。请注意,这个k’是后验分布的样本,强盗最有可能获得报酬。随着我们越来越担心哪个是最好的强盗(因为我们收集更多数据!),我们会更频繁地选择这个强盗 - 这正是我们想要的。接下来,我们计算出计算后验分布的细节。
4.3.2 Beta / Bernoulli模型
在我们的设置中,我们使用伯努利分布作为报酬分布(我们想要0/1奖励)。我们选择Beta系列的先前分布,因为它与Bernoulli分布的共轭:
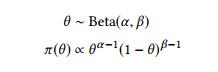
由于强盗k是独立的(通过假设),我们可以独立地更新它们的后验分布。对于每个θ~k~,先验取为θ~k~ ~ Beta(α~k~,β~k~)。 θ~k~的似然函数是Pr(n~k0~,n~k1~ | θ~k~)=θ~k~^nk1^(1-θ~k~)^nk0^。我们计算后验密度为:
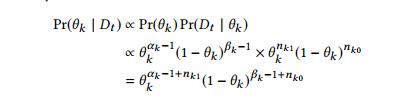
因此θ~k~| D~t~ ~ Beta(α~k~+ n~k1~,β~k~+ n~k0~)。使用这个表达式,我们可以用每轮后观察到的数据更新我们的后验分布,并使用上述采样方法选择下一个强盗(下一个变异器)。
在我们的模糊测试设置中,上述过程非常简单。为了更新我们的后代,我们只需要跟踪每个操作员k在生成成功(n~k1~)或不成功(n~k0~)输入时涉及的次数。
4.3.3信用分配
有一个轻微的并发症;在一个标准的多武装强盗设置中,每个强盗手臂的拉力都会立即转化为结果 - 0或1奖励。通过这种方式,我们可以将分数准确地分配给相应的强盗。但是,在我们的场景中,我们在查看输入是否导致额外的代码覆盖之前,采样任意数量的突变(参见算法1的第8行)。这意味着我们可以看到许多不同的变异操作符(最多128个,给定AFL的默认参数)参与创建新输入。有了这个,很难为每个涉及的突变分配适当的奖励,因为不清楚究竟哪个突变操作员导致成功(或失 败)。如果最终结果成功,我们是否为每个变异算子分配得分为1?
当同一个突变操作出现多次时会发生什么?这被称为信用分配问题,它略微混淆了上述方法。但是,我们通过稍微改变一下,我们可以解决这个问题。我们假设突变数量的高变化是有问题的;如果相反,AFL选择较小的,恒定数量的突变(即用一个小常数替换算法1的第8行的循环迭代计数),信用分配的效果将会减少。为此,我们将返回4.2节中使用的训练程序集。就像我们从数据中学习了一个良好的固定变异分布一样,我们可以类似地学习一个很好的小常数,以适应变异算子的数量。如果具有固定数量突变的相应AFL的表现与AFL(或FidgetyAFL)一样好或更好,那么它可以作为我们的Thompson采样实现的良好基础。可以在第6.1节中找到用于估计应用的突变数量的实验设置和结果。
5 数据集
我们利用两个程序数据集来突出我们方法的有效性:DARPA Cyber Grand Challenge二进制文件[7]和LAVA-M二进制文件[10]。
5.1 DARPA网络大挑战
DARPA网络大挑战二进制文件是由DARPA发布的一套200个程序,作为开放挑战的一部分,用于创建自动修改,验证和修补错误的工具。挑战发生在2016年,许多竞争团队使用像AFL这样的灰盒模糊器,以及其他符号执行工具。
作为挑战的一部分发布的200个二进制文件中的每一个都是由人类编写的,并且每个程序具有广泛不同的功能。有些二进制文件是简单的,用于排序或执行计算器操作的简单程序的变体,但许多程序是任意复杂的(如4.1节中的纯文本HTTP服务器),跨越数百行。但是,所有这些二进制文件的共同之处在于,每个二进制文件都包含一个或多个错误,由程序编写者记录。这些错误是很自然的,因为它们是人类实际编写的编程错误,因此使这个数据集成为用于对模糊测试应用程序进行基准测试的理想测试套件。这些错误包括简单的错误,例如一个错误或者释放后的使用,但是许多错误很复杂并且深藏在程序中,并且只能通过全面探索找到;例如,考虑4.1节中的程序ASCII_Content_Server.c。此程序中的一个错误(有3个)是一个空指针解除引用,只有在放入超过一定大小的多个页面后执行“VISUALIZE”命令后才会发生 - 这样的漏洞依赖于几个链接的交互是常见的CGC数据集中的错误模式,再次使其成为用于对模糊器进行基准测试的优秀测试套件。
虽然作为DARPA CGC数据集的一部分发布了200个二进制文件,但我们只使用接受STDIN输入的150(分成75/75训练和测试程序),而不是命令行参数,或通过文件。这是为了简单 - 允许我们的AFL版本与剩余的二进制文件接口,我们需要重写每个程序,或者构建一个特定于程序的预处理器/加载器。然而,我们发现150个程序足以从我们的模糊测试结果中得出结论。此外,虽然最初的CGC二进制文件是为一个名为DECREE的DARPA特定操作系统发布的,但我们使用为x86 Linux操作系统编译的二进制文件的移植版本。可以在此处找到每个二进制文件的完整C代码和跨平台编译说明:https://github.com/trailofbits/cb-multios。
5.2 LAVA-M
我们还利用了LAVA-M程序数据集[10],这4个程序取自GNU Coreutils套件,注入了数千个合成缺陷。这个数据集近年来已经变得流行,用于对复杂的白盒模糊器和符号执行工具进行基准测试,以及某些灰盒模糊器(以及AFL的一些变体)。 LAVA-M二进制文件还带有易于重复删除崩溃的工具,允许我们报告模糊器发现的实际错误。 LAVA-M二进制文件中的合成错误非常复杂,位于程序的各个深处(意味着随机输入很可能不会出现这些错误)。
具体来说,LAVA-M数据集由GNU Coreutils版本8.24的以下四个程序组成:1)base64,使用-d(解码)选项运行,2)md5sum,使用-c选项运行(检查摘要),3)uniq,和4)who。这些程序分别注入28,44,57和2265个错误。注入LAVA-M程序的所有错误都属于以下类型:仅当程序输入缓冲区的某个偏移与4字节“魔术”(随机)值匹配时才会触发的错误(有关详细信息,请参阅第10页的第10页) ])
6 实验结果
在本节中,我们提供了我们运行的每批实验的详细信息。以下许多实验包括比较许多不同的策略(即Thompson Sampling与FidgetyAFL,vs. AFL)。对于我们的许多实验,我们将AFL和FidgetyAFL作为基线进行评估 - 在这些情况下,我们将FidgetyAFL视为我们的最佳基线,因为它具有明显更好的性能。除了报告基于每个程序的策略表现最佳的总计数之外,我们还报告相对覆盖率,该指标松散地衡量一个策略相对于其他策略的好坏程度(因为AFL没有检测到程序给我们正确的基本块覆盖统计):让s对应给定的策略,t 给定的时间间隔,code_path~t~是策略 s 在时间 t 发现的唯一代码路径的数量。然后,单个程序的相对覆盖率rel-cov可以计算为:
$$
rel-covt (s) =\frac
{code_paths_t (s)}
{max_{s′}[code_paths_t(s′)]}
$$
或者找到的策略s的代码路径数之间的比率,以及所有策略中代码路径的最大数量。我们在所有程序中报告此数字的均值/标准误差。此外,为了更好地了解每个模糊运行的一般故事,我们在总时间的每个四分位数上报告统计数据(例如,在24小时运行的6,12,18和24小时)。请注意,这是一个相对统计量,估计在一个时间间隔;这意味着这个数字可能会在不同的时间间隔内针对特定策略进行波动,因为两种策略之间的差距可能会增大或减小(表3中就是这种情况)。
所有以下实验都在运行Ubuntu 14.04的机器上进行,具有12 GB的RAM和2个内核。在开始模糊测试之前,我们从我们正在测试的二进制文件中删除所有字符串常量,以在模糊测试期间用作字典条目。
6.1估计sample_num_mutations
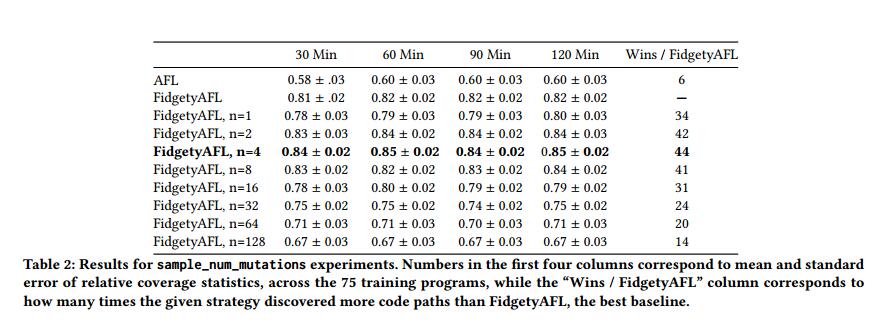
对于我们的Thompson采样实验,我们需要通过为sample_num_mutations(算法1的第8行)提供固定(理想情况下很小的)返回值来解决4.3.3节中的Credit Assignment问题。为了估计这个值,我们提出以下实验:设n是AFL运行的堆积突变的数量。在固定时间内从AFL通常采样的值范围内运行多次AFL的试验,固定值为n(回想起AFL在{2^0^, 2^1^,… 2^7^}中均匀采样)。然后,选择性能最接近(或优于)标准AFL的n。
表2中的结果显示了在2小时模糊测试运行中每30分钟n的不同固定值的相对覆盖率统计。请注意,对于FidgetyAFL,我们的修改值为n而不是对常规AFL,就像之前的工作一样,我们发现FidgetyAFL始终比AFL表现更好。这些统计数据是在75套CGC二进制文件中收集的。值得注意的是,n = 2,n = 4和n = 8的固定值表现出比FidgetyAFL更好的性能,FidgetyAFL从一系列值均匀采样。进一步观察数据,我们决定使用n = 4来构建我们的方法,因为它的性能略好于n = 2和n = 8。
6.2学习基础经验分布
接下来,我们根据第4.2节估计变异算子的良好平稳分布。我们使用第4.2节中概述的程序估计这种“经验”分布(我们将通过本文的其余部分参考)。也就是说,我们在训练二进制文件上运行FidgetyAFL,并计算每个变异操作符参与创建成功输入的次数(改进代码覆盖率)。然后, 我们将这些计数标准化,以得出我们的最终经验分布。我们通过用FidgetyAFL模拟75个训练二进制文件24小时来执行我们的训练,每3分钟倾倒一次记录统计数据。经验分布的结果可以在下一节中找到。
6.3 24小时实验
我们在DARPA CGC和LAVA-M二进制文件上运行AFL,FidgetyAFL,Empirical distribution fuzzer和Thompson Sampling模糊器,每次24小时。 Thompson Sampling实验遵循第4.3节中概述的程序。利用6.1节中的n = 4的固定值,我们直接从模糊运行期间收集的数据中估算出4.3节中的参数θ~k~。我们以均匀的mutator分布开始每个Thompson Sampling运行,以及统一的先验(我们使用β分布,其中α= 1且β= 1000作为每个臂的先验)。然后,每隔10分钟,我们通过从更新的后验采样来更新分布,使用我们迄今为止观察到的成功/不成功运算符的计数进行估计。结果如下:
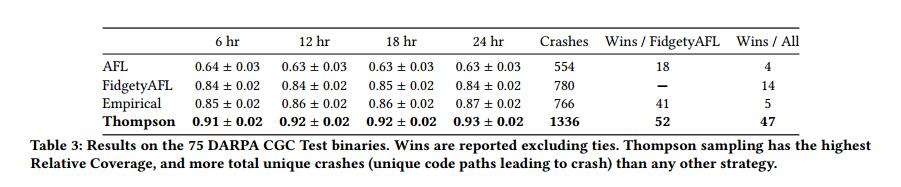
6.3.1 DARPA Cyber Grand Challenge
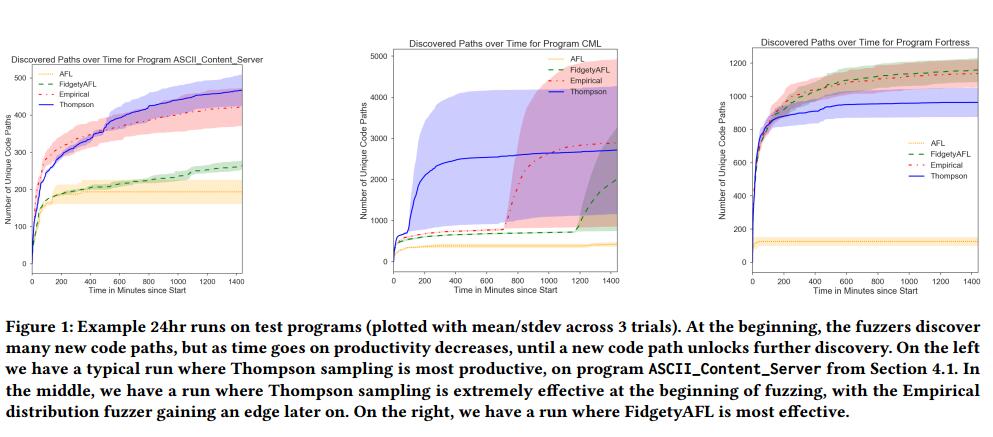
表3包含DARPA CGC实验的结果。我们报告6,12,18和24小时标记的相对覆盖率数字以及总赢数。此外,我们还报告了在24小时模糊测试期结束时发现的唯一崩溃次数。回想一下,独特的崩溃是输入操作一个导致崩溃的唯一代码路径的输入 - 对于程序中的每个错误,可能会有数百个独特的崩溃(因为您可以通过遍历不同的程序路径来达到相同的错误)。我们提供的图表显示了图1中三个不同的CGC二进制文件随时间的变化。
6.3.2 LAVA-M
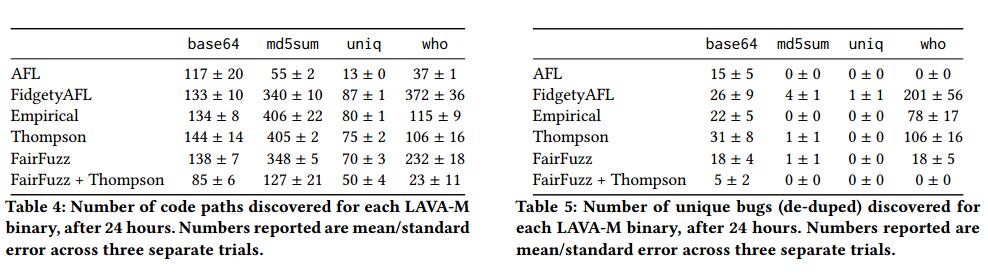
表4报告了在3个独立的24小时试验中为每个策略发现的代码路径数的平均值和标准误差(由于数据集的小尺寸,我们在此处进行了额外的试验)。表5报告了每个模糊器发现的可验证错误数量的平均值/标准误差,再次是3次单独的24小时试验(此处,LAVA-M使我们能够对崩溃进行重复删除,因此我们报告错误而不是崩溃)。
6.4汤普森抽样和FairFuzz
FairFuzz [18]是最近推出的基于AFL的工具,通过智能的数据驱动方法优化AFL的核心功能,用于学习算法1中的pick_input和sample_mutation_site功能。具体来说,FairFuzz通过优先排序队列来提高模糊效率罕见的分支,或被测试的程序的一部分未被许多发现的输入所触及。此外,FairFuzz执行分析输入中的哪些字节触发某些分支行为 - 一种估计的污点跟踪。在这样做时,FairFuzz学习输入字节上的掩码,迫使AFL单独留下某些字节(即标题或校验和),同时将突变聚焦在更易变的部分上。在最初的FairFuzz论文[18]中,作者表明他们的方法比AFL,FidgetyAFL和另一种AFL变体AFLFast [4]显着更有效。
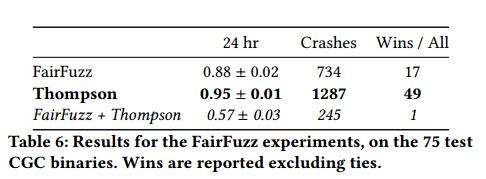
考虑到这一点,我们想回答另外两个问题:1)Thompson采样方法比FairFuzz背后的方法更好,2)FairFuzz背后的优化是Thompson Sampling的补充。为了探索这一点,我们进行了额外的实验,在我们的75个DARPA CGC二进制文件的测试集上运行FairFuzz(带有推荐的配置)。此外,我们将Thompson Sampling的更改移植到FairFuzz,并在同一个二进制文件上运行这个新的FairFuzz + Thompson采样模糊器。最后,我们根据相对覆盖率和发现的独特崩溃对三种策略进行了比较。表6报告了在对75个CGC测试二进制文件中的每一个进行24小时模糊测试之后的FairFuzz实验的结果。汤普森的抽样似乎在崩溃和代码覆盖方面都具有显着的优势,在所有二进制文件中比FairFuzz多出500多次崩溃,并且获得的覆盖率提高了7%。然而,特别有趣的是,在将FairFuzz优化与Thompson采样优化相结合而不是估计变异算子分布时,性能有显着下降。表4和表5显示了LAVA-M二进制文件上的FairFuzz结果;结果再次混乱,Thompson Sampling在4个二进制文件中的3个中表现优于FairFuzz。然而,这些实验与CGC实验相呼应,因为合并的FairFuzz + Thompson模糊器的性能有显着下降。
7 讨论
总体而言,Thompson Sampling方法表现非常出色,在绝大多数二进制文件中以最大的优势击败了最佳基线,FidgetyAFL和FairFuzz。特别是在DARPA CGC二进制文件中,Thompson Sampling模糊器显示相对于FidgetyAFL的覆盖率提高了近10%,同时还发现了所有75个测试二进制文件中的1336个独特崩溃,几乎是任何其他模糊器发现的数量的两倍。此外,在75个二进制文件中,在52个二进制文件上它比FidgetyAFL发现更多的代码路径(不包括那两个策略发现相同路径数的二进制文件)。看一下图1中的图表,我们看到通常情况下的Thompson Sampling以相对显着的余量击败FidgetyAFL / AFL(在ASCII_Content_Server等程序的情况下,在某些情况下,可以增加数千个代码路径(在这种情况下)除了Thompson Sampling结果之外,我们还看到估计的经验分布模糊器表现得相当不错,在相对覆盖率方面超过FidgetyAFL约3%。
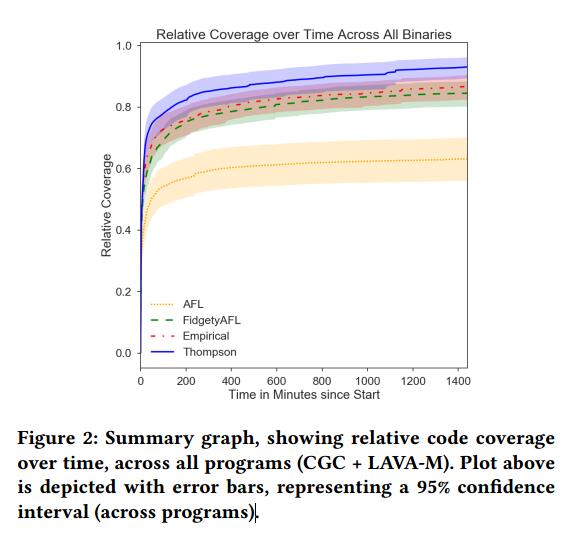
话虽这么说,在DARPA CGC二进制文件中,它不能比基线更多的崩溃。图2显示了相对覆盖率随时间变化的总结图,评估了Thompson采样,经验分布以及所有二进制文件中AFL的两个版本(CGC + LAVA-M),误差条表示程序间95%的置信区间。我们看到Thompson Sampling在每个时间步都都胜过其他策略,并且随着模糊测试的继续,它的表现优于其他策略。
汤普森采样不是银弹;有些程序比FidgetyAFL较低(即表3中提到的14个程序,以及图1中的最后一个图表)。使用LAVA-M二进制文件进一步探索了这一局限性,我们发现Thompson Sampling方法获得了不冷不热的结果。在二进制文件base64和md5sum上,Thompson采样方法能够在剩下的两个二进制文件uniq和FidgetyAFL获胜的情况下获得更多代码路径,在某些情况下可以大幅度获胜。对此的一个可能的解释是由于我们为Thompson Sampling做出的信用分配调整 - 通过将变异算子的数量变为一个小常数(在我们的例子中,每个输入运行4个突变),我们实际上限制了我们模糊器的表达能力。然而,FidgetyAFL基线是不受约束的,并且在某些情况下可以创建与父母相差多达128个突变的输入,从而触发有限突变不能的代码的某些部分。这为未来的工作开辟了可能的途径;绕过信用分配问题并在任何选择的sample_num_mutations中学习自适应分布将允许模糊器比在这项工作中开发的更强大。此外,当遇到崩溃时,我们看到了类似的趋势,Thompson采样仅在base64二进制文件上进行了更多的计算。然而,重要的是要注意碰撞中的高度差异 - 这再次表明LAVA-M数据集的合成性质。因为每个错误仅由输入缓冲区的4个字节的单个设置触发,所以给定运行是否发送某些错误是非常随机的。这似乎表明LAVA-M二进制文件更有利于测试符号执行工具和白盒模糊器,它们实际检查代码中的分支条件,并象征性地求解输入以通过某些条件;对于像AFL和AFL变体这样的随机过程,它没有提供最可解释和最终的结果。
最后,与FairFuzz相比,我们看到Thompson Sampling在相对代码覆盖率和所有75个CGC二进制文件中发现的崩溃方面具有显着的优势。与选择队列输入等其他优化相比,这再次表明了突变分布对灰盒模糊测试的影响。特别有趣的是,当结合两个看似正交的优化(FairFuzz的输入和变异位点选择,以及Thompson Sampling的变异算子选择)时,我们发现性能显着下降。虽然不幸,但可能的解释是由于FairFuzz如何选择输入与Thompson Sampling如何估计其在变异器上的分布之间的脱节。 FairFuzz优先考虑执行程序稀有分支的输入 - 输入只占总队列的一小部分。但是,Thompson Sampling根据队列中的所有输入估计其在mutators上的分布。因此,Thompson Sampling分布与FairFuzz选择输入的最佳分布不同。为了解决这个问题,未来工作的一个可能途径是学习通过变换器的输入条件分布 - 通过学习每个输入的不同分布,可以学习更精细的策略来选择变异器,绕过这种分布不对称。
8 结论
在这项工作中,我们提出了一个系统,用于将机器学习和基于强盗的优化与灰盒模糊测试中的最先进技术相结合。利用Thompson Sampling自适应地学习变异算子的分布,我们能够显示出许多最先进的灰盒模糊器,如AFL,FidgetyAFL和最近发布的FairFuzz。虽然我们的方法不是一个能够在所有程序模糊中获得最佳结果的灵丹妙药,但它适用于许多真实世界的复杂程序中的绝大多数情况,并且在某些情况下,可以达到几个数量级,相当于数百个代码路径和崩溃比其他基线。我们的实验最终表明,通过数据驱动的机器学习技术来改进现有的模糊测试工具(以及开发新工具!),以适应各种不同的程序,可以获得显着的收益。